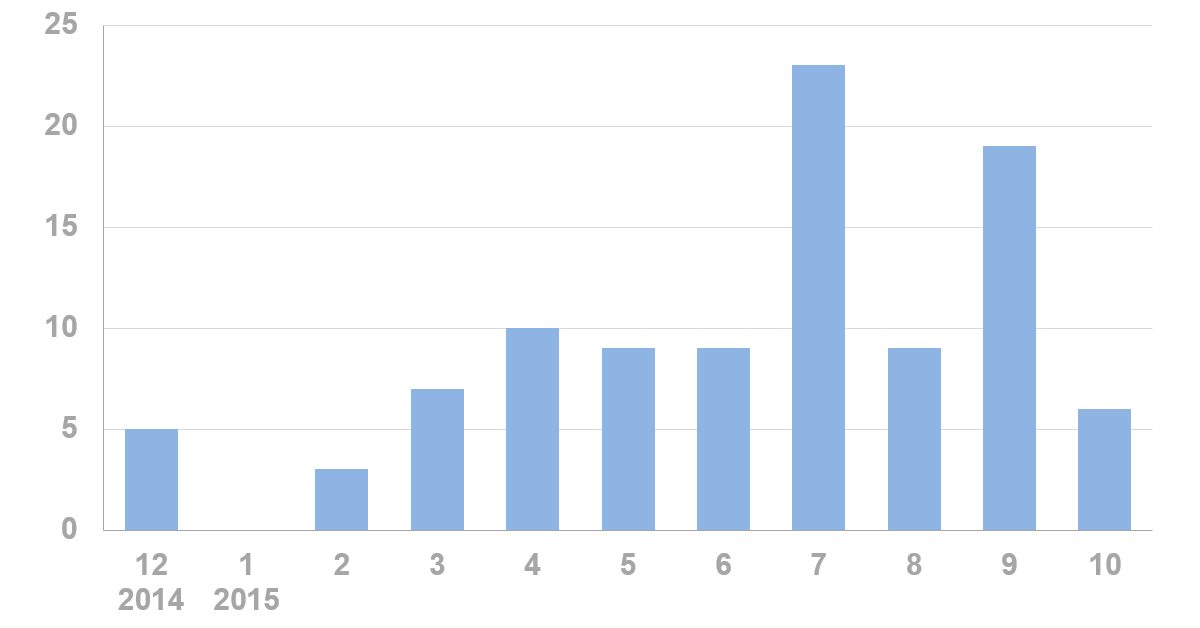
作者:《青年醫學研究論壇 2015》講者 陳天心 醫師

我想,自己可能是去年少數沒寫心得的講者,認識我的人都知道,我罹患的是「超強拖延症」,非到緊要關頭不會做事,特別是沒有動力的事情。
不過我覺得,去年參加《青年醫學研究論壇 2015》聽我演講的人,都知道我之前完整的研究經歷,我也想把 2015 年到 2016 年的收穫整理,和大家分享,主題則是鮮少有人探究的「臨床醫師做研究的代價」。
大家都想做醫學研究、發表論文,但是網路上只聽聞研究者成功的一面,卻很少探討醫師做研究必須付出的代價,於是我想從自身的經歷跟大家說明。